TIDY3D
FDTD AND MORE



Hardware Acceleration for FDTD Simulations
Why are simulations important?
Computer simulations are an essential tool in the development, design, and engineering of devices in emerging industries such as optics, photonics, quantum computing, and wireless technologies. Simulations give an engineer the power to model the workings of the device without needing to invest time, money, and energy into the fabrication, testing, and measurement of the physical device. This, in turn, enables rapid iteration on design ideas, fine tuning of device parameters, and validation of devices before they are fabricated and used in production.
The simulation of electromagnetic phenomena is usually achieved using the finite- difference time-domain (FDTD) method, which gives a detailed picture of the internal workings of the device by solving the fundamental equations that describe classical electrodynamics. This generality and wide applicability means that FDTD simulations are one of the most important tools for any photonic device engineer who needs to quickly and accurately model their devices.
What are the challenges with FDTD simulation?
The main challenge with FDTD simulations is that the full and accurate modeling of a device generally requires an extremely large amount of computing power due to the sheer number of spatial and temporal unknowns present. As a result, the time required to complete a simulation may be significant, and the physical size of the device being modeled is practically limited.
Much effort is therefore put into circumventing these issues. One such widely used approach is to break the device up into smaller components, which may be modeled individually before the results are “stitched” together to approximate the full system. While this gives an approximation to the overall working of the device, it neglects the coupling between components, which introduces significant error.
Another common approach is to apply an approximation to the device that results in a simulation with less demanding computational requirements. For example, one might approximate a three-dimensional photonic integrated circuit by a two-dimensional representation using an effective medium theory. Again, this approach may give a decent picture of the workings of the device, but also suffers from significant error introduced by the approximation.

Accelerating FDTD
Rather than introducing approximations to the device and its modeling, an alternative approach is to examine the nuts and bolts of the simulation technology itself to improve the performance of the computation being performed. A few approaches to accelerating FDTD in this way include:
Algorithm design.
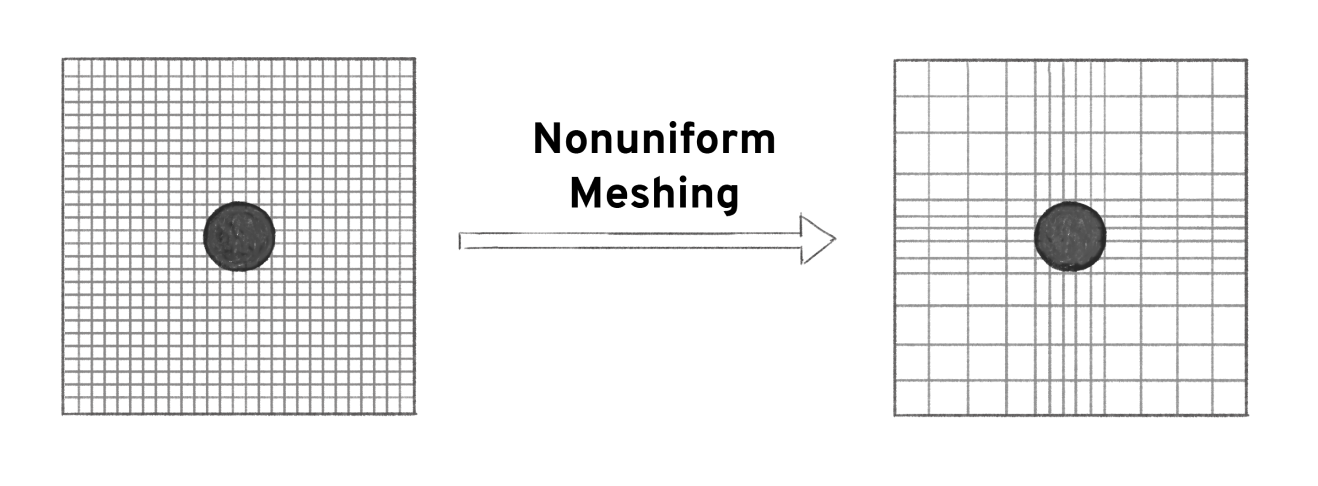
The FDTD algorithm solves Maxwell’s equations in their most basic and general form. However, there are several techniques that may be used to augment the algorithm to improve its performance. For example, applying a subpixel averaging of physical structures in the system enables higher accuracy modeling at lower resolution. Additionally, nonuniform meshing allows one to more efficiently discretize the space to place higher resolution where it is needed. Incorporating these techniques, among others, into the FDTD solver can have a significant effect on speeding up the simulation and reducing the number of unknowns needed to solve.
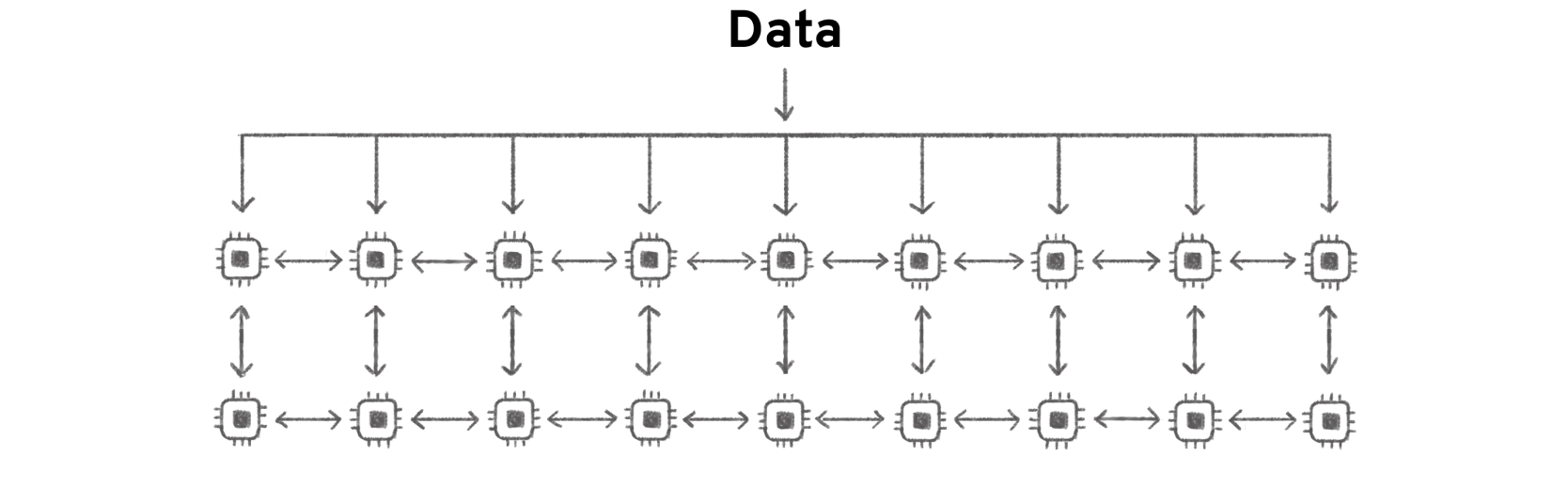
Parallelism
As simulations grow in size, the computation must be split over an increasing number of individual processors. While the number of available processors will put an upper limit on the achievable simulation size, a main bottleneck to accomplishing faster simulation speed quickly becomes the transfer of information between processors. A major challenge in accelerating FDTD simulations is how to engineer not only the computing hardware architecture, but also the strategy for splitting the simulation between processors in a way that minimizes this information transfer bottleneck.
How does Flexcompute approach FDTD acceleration?
As we can see, there are many fine details that go into making FDTD simulations as efficient, scalable, and fast as possible. At Flexcompute, our approach to FDTD simulation is to consider each aspect of the simulation both individually and as a combined system with the overall goal of optimizing performance. Our FDTD implementation is optimized for parallel processing to maximize processing speed and minimize the information transfer between workers. Each simulation is analyzed to determine the paralellization strategy that mostefficiently utilizes our large pool of compute resources. Finally, our solver implements the most state of the art algorithms for accomplishing the highest accuracy FDTD simulations with the minimum compute requirements.
The resulting solver (Tidy3D) is demonstrably over 100x faster than equivalent CPU-based FDTD solvers. This enables simulations to finish within minutes whereas they formerly would take days to complete. The effect on our customers’ product development pipeline is revolutionary, as they are able to iterate on designs within days instead of months and simulate devices that were previously too large to even handle using their previous tools.
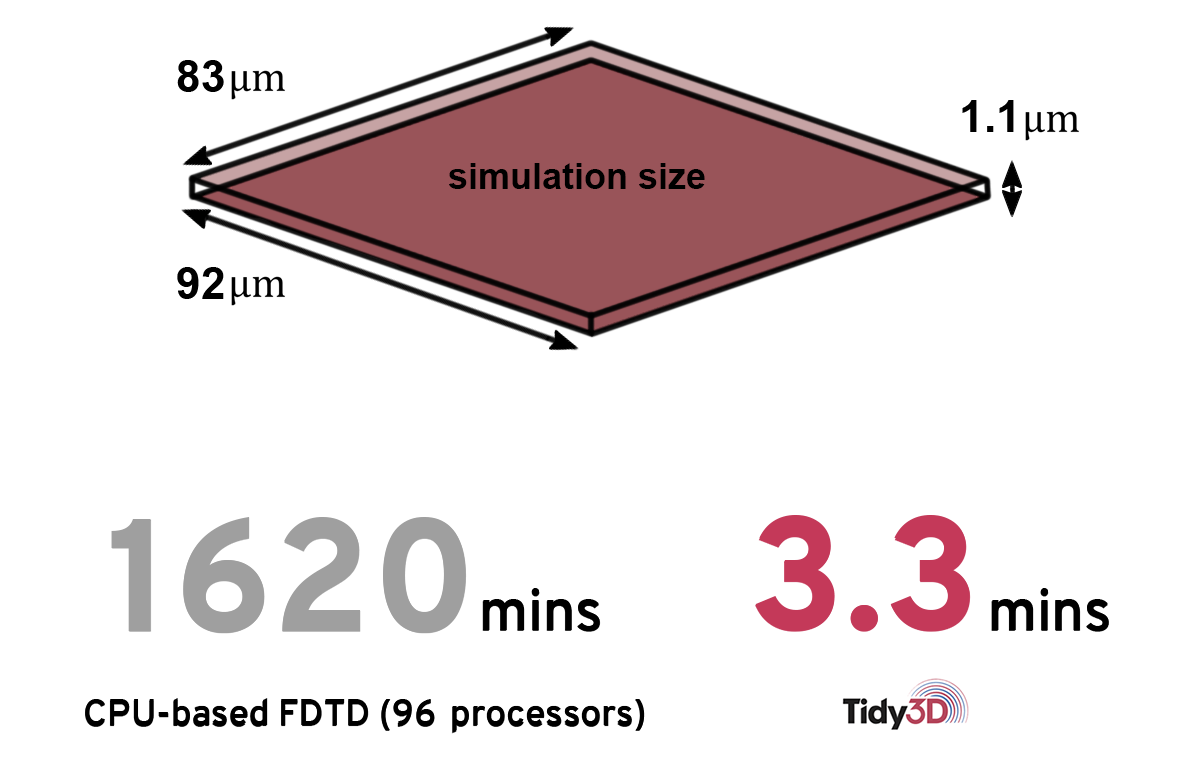
Expedite the design of photonic integrated circuit
Speed validation by a customer shows that their simulation of a large photonic integrated circuit completes in just over 3 minutes compared to previous simulations taking 27 hours on a 96-core instance running conventional FDTD.
Get a Demo* Speed-up varies case by case. The advantage of Tidy3D is more prominent on larger simulations.
Learn More
If you are looking for a turn-key solution to reduce your research, design, and prototyping activities by orders of magnitude, reach out to schedule a demo of Tidy3D today.

