TIDY3D
LEARNING CENTER













Inverse Design in Photonics Lecture 3: Adjoint Optimization
By Tyler Hughes, Zongfu Yu and Shanhui FanIn this lecture, we show how to use the previously introduced “adjoint variable method” to perform gradient-based optimization of a focusing lens. We set up a simple device based on a pixellated array of permittivity values, compute the gradient of this array with respect to the focusing strength of our lens, and then perform an optimization to achieve a final device that focuses light successfully.
Adjoint Optimization Demo¶
In this tutorial notebook, we will use the tidy3d.adjoint plugin to demonstrate the inverse design of a lens using the principles outlined in the previous lectures.
The main documentation for the adjoint plugin can be found here as well as a handful of demos of adjoint optimization in action, such as for desigining a grating coupler or a mode converter.
Set Up¶
First, we will set up the basic parameters of our simulation. We will define a 2D simulation domain with a central design region consisting of a grid of rectangular regions where we may vary the relative permittivity between that of vacuum and that of our lens material. Using the adjoint plugin, we compute the gradient of the lens focusing with respect to the permittivity of each grid cell. Then we use this gradient to update the grid cell permittivities in the direction of maximizing focusing strength. This process is repeated until a final design is achieved.
import matplotlib.pylab as plt
import numpy as np
import tidy3d as td
# in addition to the regular tidy3d package, we also import the adjoint plugin
# this gives us special tidy3d components that track derivative information
import tidy3d.plugins.adjoint as tda
# we also import the web run function from the adjoint plugin, which lets us use the adjoint plugin
# on the server side to compute gradient information efficiently
from tidy3d.plugins.adjoint.web import run_local as run
# for the rest of the process, we use the "jax" package to define our objective function
# and take derivatives using automatic differentiation
import jax
import jax.numpy as jnp
# source info
wavelength = 1.0
freq0 = td.C_0 / wavelength
fwidth = freq0 / 10
run_time = 100 / fwidth
# geometry into
lens_thick = 1.5575563445 * wavelength
lens_width = 5.575563445 * wavelength
dist = 2.3 * wavelength
buffer = 1.0 * wavelength
# simulation size
Lx = lens_thick + 2 * buffer + 2 * dist
Ly = lens_width + 2 * buffer
Lz = 0.0
# material information
ref_ind_lens = 1.5
eps_lens = ref_ind_lens ** 2
# lens discretization
nx = 33
ny = 93
dl = wavelength/20
MNT_NAME_FOCUS = "focus"
MNT_NAME_FIELD = "field"
# minimal thickness
min_thick = dist * (np.sqrt(1 + (lens_width/2/dist)) - 1)
print(f'minimum thickness should be {(min_thick/wavelength):.2f} wavelengths')
minimum thickness should be 1.12 wavelengths
Next, we will define the source and field monitor components for our simulation.
source = td.PointDipole(
center=(-lens_thick/2 - dist, 0, 0),
source_time=td.GaussianPulse(
freq0=freq0,
fwidth=fwidth,
),
polarization="Ez",
)
fld_mnt = td.FieldMonitor(
center=(0,0,0),
size=(td.inf, td.inf, 0),
freqs=[freq0],
name=MNT_NAME_FIELD,
)
focus_mnt = td.FieldMonitor(
center=(lens_thick/2 + dist, 0, 0),
size=(0, 0, 0),
freqs=[freq0],
name=MNT_NAME_FOCUS,
fields = ["Ez"]
)
Next, we write a function to generate the JaxCustomMedium structure that defines our lens as a pixellated grid as a function of an array grid permittivity values. We also write a function generate the JaxSimulation from the same inputs. Separating these as functions makes it easier to organize our code for taking derivatives later.
def make_lens(eps_array: jnp.array) -> tda.JaxStructure:
"""Make a lens structure out of the grid permittivity values (nx, ny)."""
# define data coordinates
dx = lens_thick / nx
dy = lens_width / ny
xmin = - lens_thick / 2.0 + dx / 2.0
ymin = - lens_width / 2.0 + dy / 2.0
xs = [xmin + index_x * dx - 1e-5 for index_x in range(nx)]
ys = [ymin + index_y * dy - 1e-5 for index_y in range(ny)]
coords = dict(
x=xs,
y=ys,
z=[0.],
f=[freq0],
)
data = eps_array.reshape((nx, ny, 1, 1))
eps_components = {}
for dim in "xyz":
key = f"eps_{dim}{dim}"
sclr_fld = tda.JaxDataArray(values=data, coords=coords)
eps_components[key] = sclr_fld
eps_dataset = tda.JaxPermittivityDataset(**eps_components)
custom_medium = tda.JaxCustomMedium(eps_dataset=eps_dataset, subpixel=False)
geometry = tda.JaxBox(
center=(0,0,0),
size=(lens_thick, lens_width, td.inf)
)
return tda.JaxStructure(
geometry=geometry,
medium=custom_medium
)
def make_sim(eps_array: jnp.array, incl_fld_mnt: bool = False) -> tda.JaxSimulation:
"""Make a simulation containing the custom lens grid."""
lens = make_lens(eps_array)
monitors = [fld_mnt] if incl_fld_mnt else []
# quick notes: the lens is differentiable, so it goes in input_structures
# also, we are differentiating with respect to the focus monitor output,
# so that goes in output_monitors
return tda.JaxSimulation(
size=(Lx, Ly, Lz),
run_time=run_time,
boundary_spec=td.BoundarySpec.pml(x=True, y=True, z=False),
grid_spec=td.GridSpec.uniform(dl=dl),
input_structures=[lens],
output_monitors=[focus_mnt],
sources=[source],
monitors=monitors,
)
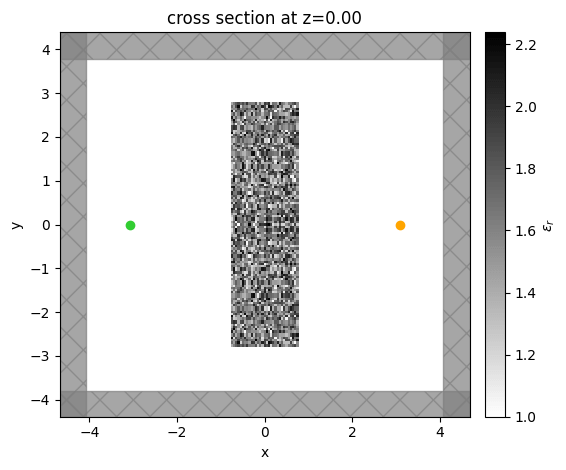
Let's make a simulation using some random starting values and make sure it looks ok.
rand_arr = np.random.random((nx, ny))
rand_arr_sym_y = (rand_arr + rand_arr[:, ::-1])/2.0
EPS_ARRAY = (eps_lens - 1) * rand_arr_sym_y + 1
sim = make_sim(EPS_ARRAY)
ax = sim.plot_eps(z=0)
Objective Function¶
Now that we have a function that generates our simulation given an array of our permittivity values, we are ready to set up our objective function for optimization. Like before, we will write this as a function over the array of permittivity values and will try to split up the logical steps as well as possible for clarity.
First, we will write a function that maps an array of parameters with values between -infinity and infinity to permittivity values between 1 and the permittivity of our lens material. This is done to ensure that we never extend outside of these values when optimizing later.
from tidy3d.plugins.adjoint.utils.filter import ConicFilter, BinaryProjector
def params_to_eps(params: jnp.array) -> jnp.array:
"""Map an array of parameters with infinity extent to an array of permittivity values within bounds."""
params_between_0_1 = 0.5 * (jnp.tanh(params) + 1.0)
# conic_filter = ConicFilter(feature_size=0.3, design_region_dl=dl)
binary_projector = BinaryProjector(vmin=1.0, vmax=eps_lens, beta=1.0)
# eps_values = binary_projector.evaluate(conic_filter.evaluate(params_between_0_1.reshape((nx, ny))).reshape((nx, ny, 1, 1)))
eps_values = binary_projector.evaluate(params_between_0_1)
return eps_values
def measure_intensity(sim_data: tda.JaxSimulationData) -> float:
"""Return the intensity at the focal spot as a function of the data from the solver."""
focal_fields = sim_data[MNT_NAME_FOCUS]
intensity = 0.0
for key in focal_fields.monitor.fields:
field = focal_fields.field_components[key]
intensity += jnp.sum(jnp.abs(jnp.array(field.values))**2)
return intensity
def objective_fn(params: jnp.array, verbose:bool = False, incl_fld_mnt: bool = True) -> float:
"""Run the full calculation from setting up sim, running, and measuring intensity."""
eps_data = params_to_eps(params)
sim = make_sim(eps_data, incl_fld_mnt=incl_fld_mnt)
sim_data = run(sim, task_name="lens_adjoint", verbose=verbose, path='data/lens_adjoint.hdf5')
return measure_intensity(sim_data), sim_data
Let's use jax to get a function that returns our objective funciton value and its gradient with respect to the eps_data array to veritfy this works as expected.
# feed in an array of very small parameters, corresponding to vacuum simulation
params_empty = -1000 * np.ones((nx, ny))
val_and_grad_fn = jax.value_and_grad(objective_fn, has_aux=True)
(val_empty, sim_data), grad_empty = val_and_grad_fn(params_empty, verbose=True)
print(f"value = {val_empty}")
print(f"grad = {grad_empty}")
View task using web UI at webapi.py:191 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-70e38201-1ae1-40f5-8af2-b6ec54c3b5b cv1'.
Output()
Output()
Output()
Output()
Output()
Output()
View task using web UI at webapi.py:191 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-fcfb4628-6d93-41b0-ab95-165656be92b 8v1'.
Output()
Output()
Output()
Output()
Output()
Output()
value = 2287817.0 grad = [[0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] ... [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.] [0. 0. 0. ... 0. 0. 0.]]
Normalize Objective function¶
Let's quickly make an objective function that is normalized by this value without a structure, so we have a dimensionless objective function that represents the "enhancement" of the intensity with respect to vacuum.
def objective_fn_normalized(params: jnp.array, verbose:bool = False, incl_fld_mnt: bool = True) -> float:
"""Run the full calculation from setting up sim, running, and measuring intensity, normalized to vacuum result."""
val_orig, aux_data = objective_fn(params, verbose=verbose, incl_fld_mnt=incl_fld_mnt)
return val_orig / val_empty, aux_data
# get the val and grad function with normalization
val_and_grad_fn_normalized = jax.value_and_grad(objective_fn_normalized, has_aux=True)
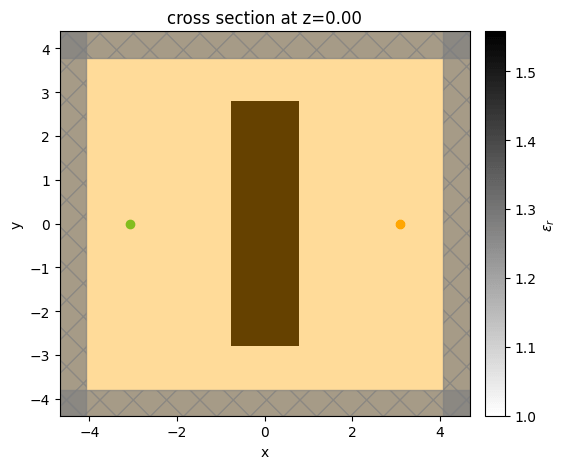
We will start our optimization with parameters slightly lower than the middle of the two permittivity limits.
PARAMS0 = -0.1 * np.ones((nx, ny))
sim_initial = make_sim(params_to_eps(PARAMS0), incl_fld_mnt=True)
sim_initial.plot_eps(z=0)
plt.show()
sim_data_initial = run(sim_initial, task_name="lens_initial", path='data/lens_initial.hdf5')
View task using web UI at webapi.py:191 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-de0f2f2d-c430-4053-a272-89c6569c3cf av1'.
Output()
Output()
Output()
Output()
Output()
Output()
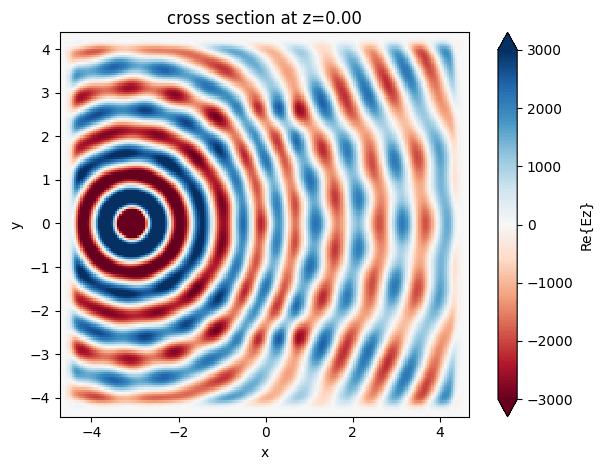
ax = sim_data_initial.plot_field(MNT_NAME_FIELD, 'Ez', 'real')
# get the starting objective function value
val0 = measure_intensity(sim_data_initial) / val_empty
val0
Array(1.9754281, dtype=float32)
Optimization¶
Now that we have our objective and gradient function defined, we can perform a simple optimization of our parameters.
We will just perform a simple "gradient ascent" algorithm in which we compute the gradient, perturb each of the parameters simultaneously in the direction that maximizes the objective function, and repeat this process several times until convergence.
# how many iterations
num_steps = 35
# magnitude of the update to the parameters in units of the gradient.
step_size = 1
step_size = 0.03
import optax
optimizer = optax.adam(learning_rate=step_size, b1=0.0, b2=0.0)
params_i = PARAMS0.copy()
eps_i = params_to_eps(params_i)
sim_i = make_sim(eps_i, incl_fld_mnt=True)
opt_state = optimizer.init(params_i)
# lists to store the values and parameters
param_vals = []
obj_fn_vals = []
grad_norm_vals = []
sims = [sim_i]
sim_datas = [sim_data_initial]
for i in range(num_steps):
print(f'step = {i + 1}')
# compute gradient
(val_i, sim_data_i), grad_i = val_and_grad_fn_normalized(params_i)
# update
updates, opt_state = optimizer.update(-grad_i, opt_state, params_i)
params_i = optax.apply_updates(params_i, updates)
grad_norm_i = jnp.linalg.norm(grad_i)
# print status
print(f'\tval = {val_i:.3e}')
print(f'\tnorm(grad) = {grad_norm_i:.3e}')
# store history
obj_fn_vals.append(val_i)
param_vals.append(params_i.copy())
grad_norm_vals.append(grad_norm_i)
eps_i = params_to_eps(params_i)
sim_i = make_sim(eps_i, incl_fld_mnt=True)
sims.append(sim_i)
sim_datas.append(sim_data_i)
step = 1 val = 1.975e+00 norm(grad) = 1.846e-01 step = 2 val = 2.534e+00 norm(grad) = 2.052e-01 step = 3 val = 3.147e+00 norm(grad) = 2.230e-01 step = 4 val = 3.805e+00 norm(grad) = 2.377e-01 step = 5 val = 4.497e+00 norm(grad) = 2.492e-01 step = 6 val = 5.213e+00 norm(grad) = 2.569e-01 step = 7 val = 5.938e+00 norm(grad) = 2.612e-01 step = 8 val = 6.661e+00 norm(grad) = 2.625e-01 step = 9 val = 7.369e+00 norm(grad) = 2.612e-01 step = 10 val = 8.058e+00 norm(grad) = 2.585e-01 step = 11 val = 8.725e+00 norm(grad) = 2.550e-01 step = 12 val = 9.367e+00 norm(grad) = 2.505e-01 step = 13 val = 9.988e+00 norm(grad) = 2.453e-01 step = 14 val = 1.058e+01 norm(grad) = 2.389e-01 step = 15 val = 1.115e+01 norm(grad) = 2.313e-01 step = 16 val = 1.170e+01 norm(grad) = 2.234e-01 step = 17 val = 1.221e+01 norm(grad) = 2.140e-01 step = 18 val = 1.268e+01 norm(grad) = 2.055e-01 step = 19 val = 1.313e+01 norm(grad) = 1.951e-01 step = 20 val = 1.354e+01 norm(grad) = 1.863e-01 step = 21 val = 1.391e+01 norm(grad) = 1.754e-01 step = 22 val = 1.428e+01 norm(grad) = 1.641e-01 step = 23 val = 1.461e+01 norm(grad) = 1.539e-01 step = 24 val = 1.491e+01 norm(grad) = 1.455e-01 step = 25 val = 1.519e+01 norm(grad) = 1.326e-01 step = 26 val = 1.545e+01 norm(grad) = 1.247e-01 step = 27 val = 1.569e+01 norm(grad) = 1.142e-01 step = 28 val = 1.590e+01 norm(grad) = 1.065e-01 step = 29 val = 1.611e+01 norm(grad) = 9.667e-02 step = 30 val = 1.629e+01 norm(grad) = 9.045e-02 step = 31 val = 1.646e+01 norm(grad) = 8.170e-02 step = 32 val = 1.661e+01 norm(grad) = 7.599e-02 step = 33 val = 1.675e+01 norm(grad) = 6.905e-02 step = 34 val = 1.688e+01 norm(grad) = 6.418e-02 step = 35 val = 1.699e+01 norm(grad) = 5.849e-02
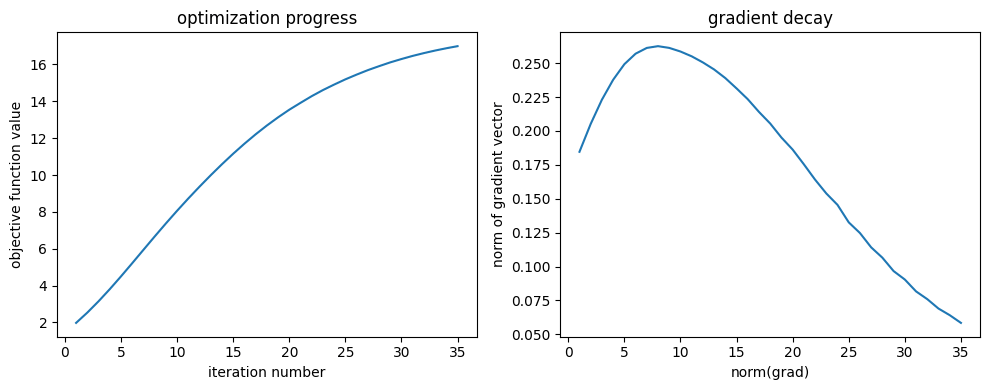
Let's visualize the optimization results and the final fields!
f, (ax1, ax2) = plt.subplots(1, 2, tight_layout=True, figsize=(10, 4))
iters = np.arange(1, len(obj_fn_vals) + 1)
ax1.plot(iters, obj_fn_vals)
ax1.set_xlabel('iteration number')
ax1.set_ylabel('objective function value')
ax1.set_title('optimization progress')
ax2.plot(iters, grad_norm_vals)
ax2.set_xlabel('norm(grad)')
ax2.set_ylabel('norm of gradient vector')
ax2.set_title('gradient decay')
plt.show()
params_final = param_vals[-1]
sim_final = make_sim(params_to_eps(params_final), incl_fld_mnt=True)
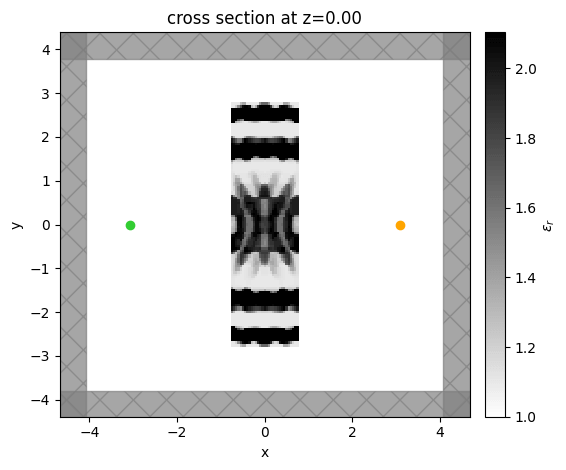
ax = sim_final.plot_eps(z=0, monitor_alpha=0.0)
sim_data_final = run(sim_final, task_name="lens_final", path='data/lens_final.hdf5')
View task using web UI at webapi.py:191 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-1d12301f-668a-462b-82d5-45d819cf54d av1'.
Output()
Output()
Output()
Output()
Output()
Output()
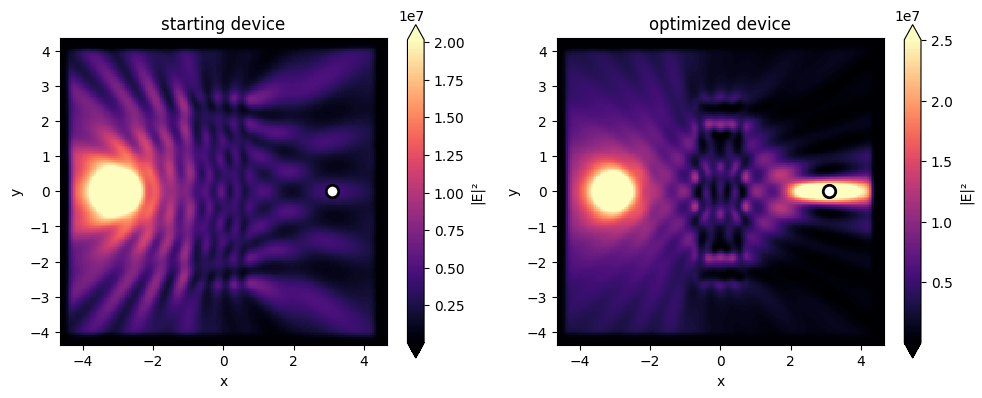
fig, (ax1, ax2) = plt.subplots(1, 2, tight_layout=True, figsize=(10, 4))
sim_data_initial.plot_field('field', 'E', 'abs^2', ax=ax1)
sim_data_final.plot_field('field', 'E', 'abs^2', ax=ax2)
x_meas, y_meas = list(focus_mnt.center)[:2]
ax1.scatter(x_meas, y_meas, s=80, c="white", linewidth=2.0, edgecolor='black')
ax2.scatter(x_meas, y_meas, s=80, c="white", linewidth=2.0, edgecolor='black')
ax1.set_title('starting device')
ax2.set_title('optimized device')
plt.show()
import matplotlib.animation as animation
from IPython.display import HTML
fig, (ax_eps, ax_ez, ax_int) = plt.subplots(1, 3, tight_layout=True, figsize=(10, 3))
def animate(i):
sim_i = sims[i]
sim_data_i = sim_datas[i]
sim_i = sim_i.updated_copy(structures=list(sim_i.structures) + [td.Structure(geometry=td.Box(size=(0.001,0.001,0.1), center=focus_mnt.center), medium=td.Medium(permittivity=eps_lens))])
sim_i.plot_eps(z=0, monitor_alpha=0.0, ax=ax_eps)
sim_data_i[MNT_NAME_FIELD].Ez.real.squeeze().plot.pcolormesh(x='x', y='y', ax=ax_ez, add_colorbar=False)
sim_data_i.get_intensity(MNT_NAME_FIELD).real.squeeze().plot.pcolormesh(x='x', y='y', ax=ax_int, add_colorbar=False, cmap="magma", vmax=0.3e8)#, aspect="equal")
# create animation
ani = animation.FuncAnimation(fig, animate, frames=len(sims));
plt.close()
# display the animation
HTML(ani.to_jshtml())
<Figure size 640x480 with 0 Axes>
ani.save('animation_basic.gif', writer='imagemagick', fps=60)
MovieWriter imagemagick unavailable; using Pillow instead.
<Figure size 640x480 with 0 Axes>
Inverse Design: Lecture 3
So today we’ll to continue our discussion of inverse design in photonics by providing a real example of an optimization of a device as enabled by the adjoint variable method.
So as an example, to design a lens, one can imagine a mathematical objective function as the simulated intensity at the focal point. More specifically, to design a lens, one would like to find a structure that maximizes the intensity for a given incident wave. One starts with a given structure as parameterized by various variables describing the device, for example, the geometry or the dialect constant of the system. Then one computes the gradient, which describes how to vary the device in a way that improves its performance. With the gradient, one can then adjust each of the structural parameters slightly along the gradient direction to improve the performance and repeat this process until convergence. Thus, it is clear that the gradient calculation is a key step in this process. In the last lecture, we described a very efficient method for computing the gradient with respect to an arbitrarily large number of parameters with only two simulations, called the “adjoint method”. This method allows one to significantly speed up, and in many ways, enable the optimization of these structures using gradient descent. In this lecture, we will give an example of how this works in practice.
We start with a relatively simple example where our goal is to design a device to focus light. We imagine a two dimensional system with a point source as indicated by the green dot on the left. Our objective is to focus the emitted light from this point source as much as possible onto the orange point on the right, which indicates a field monitor. To accomplish this, we put a device in between the source and monitor as vacuum will not do this for you. Our problem thus becomes to design this device to maximize the focusing at the monitor location. We assume our device is described by a permittivity distribution within it’s rectangular region, which we can set arbitrarily to accomplish this objective.
To start the optimization, we simply put a dielectric slab between the source and the monitor. The relative permittivity of this slab is 1.625, which is halfway between 1 (vacuum) and 2.25, which is a reasonable value for glass. In the middle panel, we show the starting electric field distribution, which shows (unsurprisingly) that the device does not focus at all. One can clearly see a cylindrical wave emanating from the point source and being perturbed a bit by the slab. Starting from this device, we iteratively update the device until it achieves focusing using the gradient information.
This slide shows the process of the full optimization algorithm as an animation. On the left is the permittivity distribution of our device at each iteration step, in the middle is the electric field corresponding to that permittivity distribution, and on the right is the intensity distribution. One can see that as we adjust the permittivity distribution inside the rectangle, the field pattern very quickly starts to exhibit this focusing behavior. This is particularly visible in the intensity distribution on the right hand side. So, in this kind of method, one can allow the computer to simply “figure out” what the optimum device configuration needs to be in order to achieve the functionality that you would like to accomplish. Now we will go into more detail about how this optimization is set up.
As mentioned, the design region here is inside of a rectangle between the point source and the measurement point. The first step is to break this design region into hundreds of pixels. We assume we can independently control the relative permittivity of the material at each of the pixels. Thus, these pixels define our design parameters that we can update during our optimization process. The adjoint variable method allows us to compute the gradient of the objective function with respect to each of these permittivity values using only two simulations! Note that there are quite a few practical considerations when setting up this optimization process, but we will talk more about these in subsequent lectures. Over the course of an optimization, one would therefore compute the gradient of the objective function with respect to the permittivity of each pixel and then update the values based on this gradient. However, there are not yet any constraints on the permittivity values, which is not realistic.
In practice, one only has control over a very small range of permittivity values. For example, if one is optimizing a glass-based structure, then the maximum permittivity one can get is the permittivity of glass (2.25). Therefore, it is useful to introduce a method to automatically constrain the permittivity to be within a minimum value and a maximum value to enable a structure that is more reasonable. For this purpose, instead of directly computing the gradient with respect to the permittivity, we constrain the permittivity between two bounds to the minimum and maximum by having an extra parameter “p” for each pixel that can span from negative infinity to positive infinity and smoothly maps to a permittivity value between our two bounds. In practice, we therefore compute the gradient with respect to these “p” values and update those in our optimization. The advantage of this approach is that you can be sure that the permittivity values of your device never extend outside of the allowed bounds.
With this parameterization, the optimization procedure is very similar to what we discussed previously regarding the relative permittivity. The only difference is that we compute the gradient with respect to the “p” parameters and update these “p” values directly.
Here we show a few plots describing the optimization progress. On the left is the objective function as a function of the iteration number, recall this corresponds to the intensity at the measurement point. We see that the objective function steadily improves its ability to focus light. On the right, we show the norm of the gradient vector as a function of iteration step, which shows that the gradient is decaying as we reach a local maximum, which makes intuitive sense given our picture of the optimization procedure. Both of these plots give a strong indication that the gradient optimization is behaving exactly as one would expect.
Lastly, we plot the final device and the corresponding intensity pattern. One can clearly see the focusing of the intensity at the monitor point. On the left, we show the dielectric structure that's generated by the computer, with a very unintuitive shape. You can see a distinctive variation, for example, along the y direction of the permittivity, which enables focusing. It is quite common that these optimization algorithms produce structures that are rather counter intuitive. In this case, one can imagine it is operating similar to a zone plate lens, but it is hard to intuitively understand how some of these final devices work in general. As a summary, in this lecture, we gave a first glimpse of how the gradient-based optimization enabled by the adjoint variable method works. There are many details that we will discuss in further lectures. One of the most important aspects is how to produce a final design that be fabricated, while we touched on this subject a little bit by constraining our permittivity values within a certain range, we will dedicate a lecture to this. Additionally, there are also many details regarding the optimization algorithm itself that are important to understand for improving performance, speed, and stability of the design process, which we will discuss further.

